|
≪対応のある場合のt検定≫…例題・問題 ■対応のある場合のt検定を用いる例
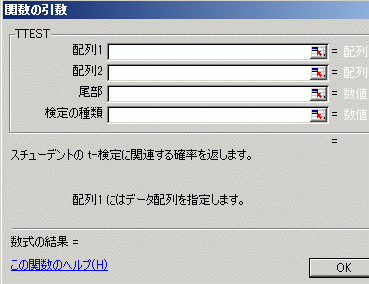
次にような場合に「対応のある場合のt検定」…「 一対の標本による平均の検定」「対応のある2群の平均値差の検定」「データに対応がある場合のt検定」とも呼ばれる…を用いる.
○1 同一の被験者に対して異なる2つの条件で測定したとき,それぞれの条件下での母集団平均が等しいかどうかの比較を行う場合
例1
表1
表1は定期健診での最高血圧の一覧表であるものとする.No欄は被験者の整理番号,A欄は昨年の定期検査時の最高血圧,B欄は今年の定期検査時の最高血圧とする.
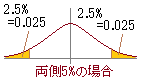
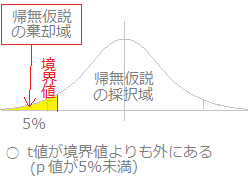
この一覧表では12人の被験者について,昨年の定期検査時と今年の定期検査時の最高血圧が対のデータとなっている. これらのデータからA欄の値とB欄の値を比較すると,A欄のデータとB欄のデータは同一被験者のデータであるので,昨年と今年という条件だけが異なることになり,昨年の最高血圧と今年の最高血圧に有意差があるかどうか調べることができる.(単にA欄とB欄のデータの件数が等しく,A欄が昨年のB欄が今年のデータであるというだけで対応のあるt検定が使える訳ではなく,A欄とB欄が同一被験者のデータとして対応があることが重要) この場合において,昨年と今年で有意差があるかどうかを調べるのだから両側検定を用いるとよい. 
※例1のような検定を行うためには,母集団についてA欄のデータ,B欄のデータ,A-Bの値が各々正規分布していることが前提となる.
取り扱っているデータがそもそも正規分布にならないという有力な学説がある場合(例えば,演歌やロックのような特定ジャンルの音楽に対する大人の好感度,数学や英語などの教科に対する生徒の好き嫌いなどを数値化したとき,値は正規分布にならない・・・好き嫌いが分かれて双峰形になる・・・という有力な学説があれば),安易に正規分布を仮定できないが,特に引っかかる事情がなければ多くの場合,母集団の値の分布,差の分布は正規分布をなすものと見なせばよい. ※このような「対応のある場合のt検定」を適用する場合には,A欄のデータとB欄のデータが等分散であるか否かによって,以後の処理を分ける必要はない. |
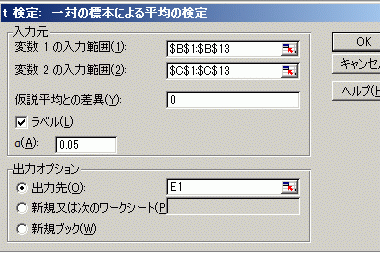
 をクリックして,B1からB13までをドラッグする(表題B1も入れるか入れないかによって「ラベル」欄にチェックを入れるかどうかが変わる)
をクリックして,B1からB13までをドラッグする(表題B1も入れるか入れないかによって「ラベル」欄にチェックを入れるかどうかが変わる)