|
← PC用は別頁
≪カイ2乗分布(χ2分布)≫ ・・・ 比率の検定[chi-square distribution]…(chiの綴りはExcelで使う) ◇簡単な例でイメージ作り(1)◇ 例1 日本人のABO式血液型の分布はおよそA型40%,B型20%,AB型10%,O型30%だといわれている.ある村で献血に応じた者のうち先着100人の血液型は次の表のとおりであった.(ただしデータは架空のもの)(考え方) もし,完全に一致していたら,次の表の期待度数で示される人数となるはずであるが,標本調査の場合には少々の凹凸はありうる.どの程度の差異ならば偶然として許容されるかと考える. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(少しだけ理屈を!) ○ 次のような観測データの分布を基準の比率と比較するには
χ2 = を,理論的な計算で求めたχ2値と比較すればよい. ○ なぜ,この方法でできるのかという数学的根拠は難しい 「n個の変数が各々独立に標準正規分布に従うとき」(自由度n),それらの2乗の和 χ2=Z12+Z22+…Zn2 は,標準正規分布(の2乗)を単純にn倍したものにはならず,自由度nのカイ分布と呼ばれるものになる.(シミュレーションにより目で確かめる方法は「仕事に役立つEXCEL統計解析」p.186〜に出ている) しかし,利用する側から見れば「前提条件に気をつけながら当てはめるだけ」で利用できる. ○ χ2分布関数は自由度に応じて関数の形が異なり,1枚の表にまとめられないので,自由度-よく使う確率(5%,1%など)からχ2を読み取るように作られている.(コンピュータではこの制限はない.)次の表では,自由度3でp=0.05に対応するχ2の値は7.815となる.  (pは右片側面積) (pは右片側面積)
○ χ2は0以上の値に対して定義され,0のとき完全一致し,差異があるほど値が大きくなる. ○ χ2分布表:[ ↓こちら ][ 非表示 ])
|
| ◇簡単な例でイメージ作り(2)◇ 例2 ある果物をA方式で育てたものとB方式で育てたものの出荷時の等級が次の表のようになったとき,これらの育て方と製品の等級には関連があると見るべきかどうか.(ただしデータは架空のもの)(考え方) A,Bが独立であるとき,分割表は次のようになる. |
||||||||||||||||||||||||||||||||||||||||
| (少しだけ理屈を!) ○ 2つの育て方が製品の等級に影響しない(育て方と製品の等級が独立なとき)ときは,次の表においてa1:a2:a3=b1:b2:b3が成り立つはずである.
a1 = 26×100/300=8.7 b1 = 26×200/300=17.3 他の値についても,期待度数を埋めることができる. ○ 各マスの (Oij-Eij)2/Eij の和 χ2= 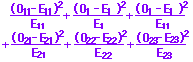 が自由度(m-1)(n-1)についての有意水準αを超えていれば,これらの方式は独立ではない(有意差がある)と言える.
○ 日常生活では,行小計に対する割合で表わした表
※この表のように,元の度数分布表(整数値)がなくて割合の数値だけになっている場合,そもそも検定はできない. |
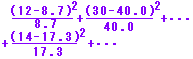
|
ここまでの■要約■ 1 ある標本の各カテゴリー(分類項目)ごとの比率が,基準の比率と一致しているかどうかを判定するものは,適合度の判定と呼ばれる. 観測度数が次の表1のようになったとき,この度数分布が表2で与えられる母集団の割合と一致するかどうかを判断するには, |
||||||||||||||||||||||||||||||||||||||||||
|
○ 分類項目1〜nはカテゴリーデータでもよいし,定量的データ(もしくはそれらの階級)でもよい. ○ 期待度数が5未満のものがあるとき,分類の項目を併合して5以上にする.(カイ2乗分布という連続曲線で近似するためには,どの期待度数も pk×N≧5を満たすことが条件とされている.) 例
|
| 2 2つの属性によって分類した分割表(クロス集計表)から,これらの分類が独立(無関係)かどうか調べるものは,独立性の検定と呼ばれる. 次の表4のような分割表(クロス集計表)が得られたとき,2つの属性が独立(無関係)かどうか・・・項目A,B,Cに差異があるかどうかを判断するには |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
※ E11〜E34は小数部分を四捨五入して整数化してもよいが,途中経過はすべて実数(小数)でおこなうので,小数のままでもよい. ※ 2×2の分割表では,期待度数のうち幾つかが4以下であっても分類の項目を併合すると意味がなくなる.この場合,標本の個数(観測度数)を大きくすることができなければ,「イエーツ(イエツ)の(連続)補正」呼ばれる方法(小さい方の期待度数に0.5を加える方法)がとられることがある.(離散分布を連続分布で近似するときに,真の値の限界を2つの整数の中央とするのと同様の考え方で,この方が経験的にも有効であるとされている.なお,列小計,行小計は変えない. 
【フィッシャーの正確確率検定について】
5よりも小さなセルの値を含む分割表に対しては,カイ2乗曲線で近似できず,カイ2乗検定をそのまま適用するのは無理がある. このような場合に対しては,「フィッシャーの正確確率検定」が適用できる.これは,条件を満たす組合せに対して直接確率計算を行うもので,理屈上は各セルの値が大きい場合にも適用できる.ただし,各セルの値が2桁,3桁になるとフィッシャーの正確確率検定では,巨大な整数の掛け算・割り算になるため,誤差がひどくなる.セルの値が大きな場合は,やはり「カイ2乗検定」が有利だと言える. フィッシャーの正確確率検定の解説は,このページ |
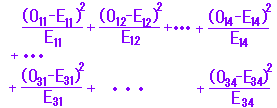
|
■例と答■
(1) [適合性の検定・・・片側検定]
さいころを600回ふったとき出た目の回数は次のとおりとなった.このさいころは正しく作られているか.有意水準5%で検定せよ.
(解答) 「帰無仮説:H0 さいころは正しく作られている. 対立仮説:H1 さいころは正しく作られていない.」とする. 帰無仮説を元に期待度数を計算すると,正しく作られたさいころは各目の出る確率が等しいから,期待度数は各々100となる.
自由度5,α=0.05のとき, χ2=11.07>1.36だから有意差はない.正しく作られていると考えられる. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(2) [独立性の検定・・・片側検定]
ある単元の授業をA方式で行った50人とB方式で行った50人に各々事後アンケート調査を行った結果は次の表のとおりであった.これら2つの方式は分かりやすさに有意差があるといえるか.有意水準5%で検定せよ.(ただしデータは架空のもの)
(参考) 新しい教育システムを考案して,その効果を確かめたいとき,計画,試作,受講の依頼などに数ヶ月かかってしまうため標本データが50人程度しか確保できないことが多い.次の表で実験群,統制群とも50人,統制群が25対25の場合に,シミュレーションしてみると,
標本数が実験群200,統制群200程度になると,もっと低いレベルで有意差が得られる. (解答) 「帰無仮説:H0 分かりやすさと教え方の方式は無関係である. 対立仮説:H1 分かりやすさと教え方の方式は関係がある.」とする. 観測度数の周辺和(行小計,列小計)を元に,帰無仮説を前提としたときの期待度数を計算する.
自由度1,α=0.05のとき χ2=3.84>2.102であるから帰無仮説は棄却されない.有意差はない. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(3) [イエーツの補正]
ある会社の製品を2つの工場で生産したものについて抽出検査をした結果,良品,不良品の度数は次の表のとおりであった.これら2つの工場の不良品発生状況について有意差が見られるか.有意水準5%で検定せよ. イエーツの補正を行って近似を良くした場合についても述べよ.(ただしデータは架空のもの)
(解答) 「帰無仮説:H0 2つの工場の不良品発生比率は同じ. 対立仮説:H1 2つの工場の不良品発生比率は同じでない.」とする. 観測度数の周辺和(行小計,列小計)を元に,帰無仮説を前提としたときの期待度数を計算する.
自由度1,α=0.05のとき χ2=3.84<4.718であるから帰無仮説は棄却される.有意差が見られる. (イエーツの補正を行う場合)
自由度1,α=0.05のとき χ2=3.84>3.227であるから帰無仮説は棄却されない.有意差が見られない. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(4) [カテゴリーの併合]
次の表は3つの地区の年齢別人口構成とする.(ただしデータは架空のもの) これら3地区の年齢別人口構成について有意差は認められるか.有意水準5%で検定せよ.
(解答) 「帰無仮説:H0 年齢別人口構成は地区によって変わらない. 対立仮説:H1 年齢別人口構成は地区によって差異がある.」とする. 観測度数の周辺和(行小計,列小計)を元に,帰無仮説を前提としたときの期待度数を計算する.
自由度4,α=0.05に対応するχ2値は9.49>2.238だから帰無仮説は棄却されない.年齢構成に有意差はない. |
|
■Excelの利用■(解説) ○ CHIDIST(カイ2乗値, 自由度) 
右図のようなχ2分布関数[chi-square distribution]において,正の数xと自由度を指定したとき,P(X≧x)となる確率を返す. 次のχ2分布表との関係では,
=CHIDIST(13.27, 4) が0.01 などとなる. ○ CHIINV(確率p, 自由度) 右図のようなχ2分布関数において,指定された自由度について,確率がp となる正の数xを返す. =CHIINV(0.05, 3) が 7.815 =CHIINV(0.01, 4) が 13.277 などとなる. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
○ CHITEST(実測値範囲, 期待値範囲) (1) 次の表のように観測度数以外に期待度数をあらかじめユーザが入力しておく.
表7
CHITEST()の実測値範囲に右のB2:G2を指定,期待値範囲に右のB3:G3を指定すると確率pが返される.
有意水準αと比較して CHITEST()>α ならば 帰無仮説採択 CHITEST()<α ならば 帰無仮説棄却 上の例(1)の問題では,=CHITEST(B2:G2,B3:G3) が0.9286 >0.05 となるから,帰無仮説が採択される. (2) 独立性の検定の場合も同様.次の表の場合,期待度数はあらかじめユーザが入力しておき,実測値範囲にB2:C3を指定,期待値範囲にB6:C7を指定すると,=CHITEST(B2:C3,B6:C7)が0.1470と>α=0.05なるので帰無仮説採択
表8
◇以上のまとめ◇・・・右片側検定の場合,次のいずれかによる ○カイ2乗値を自分で求めるとき CHIDIST(カイ2乗値, 自由度)<α ならば棄却域 実演 表7でCHIDIST(H5, 5)=0.9286>0.05 だから帰無仮説採択 CHIINV(α, 自由度)<カイ2乗値 ならば棄却域 実演 表7でCHIINV(0.05, 5)=11.07>1.36 だから帰無仮説採択 ○カイ2乗値を自分で求めないとき CHITEST(実測値範囲, 期待値範囲)<α ならば棄却域 (自由度は向こう合わせ) 実演 表7でCHITEST(B2:G2, B3:G3)=0.9286>0.05 だから帰無仮説採択 |
|
■Excelの利用.例と答■
(1)
(解答) 〜検算の意味で幾通りかやっておくとよい.〜さいころを60回振って出た目を記録した.このさいころは正しく作られているかどうか有意水準5%で検定せよ.
次の表のように,あらかじめ期待度数を入力しておく.
CHIDIST(H5, 5) = 0.038<0.05 だから,さいころは正しくない. 解2 CHIINV(0.05, 5) = 11.07<11.8 だから,さいころは正しくない. 解3 CHITEST(B2:G2,B3:G3) = 0.038<0.05 だから,さいころは正しくない. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(2)
(解答) 〜検算の意味で幾通りかやっておくとよい.〜あるコンビニの3支店での1日の売り上げ個数は,次の表のとおりであった.この3支店の売り上げ個数の比率には有意差があるか.有意水準5%で検定せよ.
次の表のように,あらかじめ期待度数を入力しておく. (CHITEST()で行うときは12行目以下は不要)
CHIDIST(F17, 6) = 0.00096<0.05 だから,有意差あり. 解2 自由度は2×3=6 CHIINV(0.05, 6) = 12.59<F17 だから,有意差あり. 解3 自由度は向こう合わせ CHITEST(B2:E4,B8:E10) =0.00096 <0.05 だから,有意差あり. |
|
(以下は参考) ≪カイ2乗分布と2項分布,正規分布の関係≫ ■カイ2乗,カイ2乗(χ2)分布とは ○ 標準正規分布に従う確率変数zの2乗がなす確率分布を自由度1のカイ2乗分布という. χ2=z2
(2乗しているので正または0の値のみをとる.)○ 標準正規分布に従う2個の確率変数z1,z2の2乗の和がなす確率分布を自由度2のカイ2乗分布という. χ2=z12+z22
(2つの変数が独立に動くので,自由度1のときと比べると縦に2倍になるのでなく横に広がった形になる.)○ 一般に標準正規分布に従うn個の独立な確率変数の2乗の和は自由度nのカイ2乗分布に従うという. χ2=z12+z22+···+zn2
※ このように「カイ2乗分布(χ2分布)」は,もともと数学的に定義された連続関数に付けられた名前である. これに対して「カイ2乗検定」に登場する「カイ2乗」はm×n分割表などにおいて各セル(窓枠)に入ったデータの観測度数(離散的なデータ)をもとに計算される式の値である. 以下においては,観測度数をもとに計算される「カイ2乗」をグラフや表で示される「カイ2乗分布」と照らし合わせことによって比率の検定ができる仕組みを考える. カイ2乗分布は図2のように自由度(degree of freedom → df と略されることが多い)ごとに異なる形をした連続型の確率分布で,x≧0の区間において定義され,与えられたxの値よりも上側に来る確率は,自由度ごとに計算されて参考書の巻末表に掲載されていることが多い.(カイ2乗分布表を調べるときは自由度dfとxの値の2つ指定しなければならない.) 図2で赤で示した自由度4(df=4)のカイ2乗分布を例として見ると,n個の確率変数が独立に動くために自由度が1のときの4倍になるのでなく(縦に伸びるのではなく)右側のすそ野の長い曲線になっており,左右非対称な山形をしている.  図1 ↓ 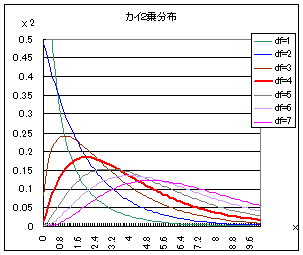 図2 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ■2つの比率に分かれる確率・・・2項分布 1回の試行で事象Aの起こる確率がp,事象Aが起る確率がq (=1-p)であるとき,この試行をN回行ったときに事象Aがm回,事象Aがn回(合計N回)起こる確率は2項定理で求められ NCmpmqn
となる.■2項分布の正規分布による近似  表1
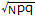 の正規分布で近似され, の正規分布で近似され,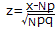 ここで,事象Aが起こる観測度数がmとなるときのχ2を求めると 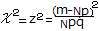 ・・・(1) ・・・(1)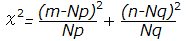 ・・・(2) ・・・(2)
(*)
(2)を変形すると(1)に等しくなることが示せる. 
一般にすべてのセル(マス目)について
 を加えたもの
を加えたもの
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ■カイ2乗の値の例
さいころを100回投げて1の目が20回出た場合に,このさいころが正しく作られたものかどうか判断したい場合を考えてみると,事象Aは「さいころを投げたときに1の目が出ること」を表し,Aは「1以外の目が出ること」を表す.確率pは1/6,qは5/6,観測度数mは20,nは80,総度数Nは100になる.
例1正しく作られたさいころでは,1の目が100÷6≒17回程度出るはずだが確率的な偶然で実際には多少の増減はある.とすれば20回なら偶然の範囲と言えるかどうか.このように指定された比率(1/6)と実際の観測度数(100のうちの20)が等しいとみなせるかどうかを判断するのが「比率の検定」の問題である.
表2
表2において期待度数はさいころを60回投げたときに出た目の回数を集計したものとする.このさいころが「どの目も確率1/6で出るように作られているかどうか」を検定するには,
(1) はじめに観測度数の他に「どの目も確率1/6で出るように作られている」という仮定を満たす場合の期待度数を計算する・・・60×1/6=10になる. これは基準とすべき確率分布が与えられている場合,したがって基準となる期待度数が与えられている場合になっている・・・適合性の検定の場合にはこのようにして期待度数が求められる. (2) 次にすべてのセル(マス目)に対してχ2を求め,その和
χ2=
(3) 検定の内容に応じてこのχ2値をχ2表と見比べて判断する.(この例では自由度5のχ2分布表を見る.)=3.40 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
例2
(1) 帰無仮説として「男女の性別によって好感度には違いがない」と仮定したときの,各々のセルの期待度数の表を作る. たとえば「男子」「よい」のセルの期待度数は,列の和27を54:46に配分したものになるべきだから27*54/100=14のように求める.(小数のままでも四捨五入して整数にしたものを使ってもよい.) これは,性別に対して独立という仮定に基づいて,周辺度数(列の小計,行の小計)から期待度数を求めていることになる.このような独立性の検定においては,帰無仮説に基づいて観測度数から周辺和を計有して期待度数を求めることになる. (2) 次にすべてのセル(マス目)に対してχ2を求め,その和 (3) 検定の内容に応じてこのχ2値をχ2表と見比べて判断する.(この例では自由度2のχ2分布表を見る.) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ■自由度と確率変数の個数 2つの事象のどちらかになる回数は2項分布で与えられるが,3つの事象A,B,Cに分かれるときの自由度を考えてみる.たとえば,ある人がジャンケンでN回手を出すときに,グーをa回,チョキをb回,パーをc回出したとき,この手の出し方は均等であったかどうか調べたいものとする. これを2段階に分けて考えて,まずAとそれ以外(BまたはC)に分かれると考えると まずAとそれ以外に分かれる確率を求めるために確率変数z1を用い,さらにBとCに分かれる確率を求めるために確率変数z2を用いるので,A,B,Cの3つに分かれる確率を求めるためには確率変数が2つ必要になる. このようにして,順次にn個の事象に分けるためには確率変数がn-1個必要になるから,自由度はn-1になる. これに対して,表4の2×2分割表で周辺度数が与えられているときは,1つのセルの値が決まれば残りのセルの値が決まるから,2×2分割表を埋めるときの自由度は1になる. 一般に表5のようにm行×n列の分割表においてセルの期待度数を求めるときの自由度は(m-1)(n-1)になる.
2項展開の繰り返しによって多項展開を行う考え方
(a+b)Nを展開したときのarbN-rの係数は2項定理によって求められ,NCrになる. そこで(a+b+c)Nを展開したときのarbsctの係数を求めるには,まず(a+(b+c))Nを展開してar(b+c)N-rの係数を求めると NCr 次に(b+c)N-rを展開するとよい. 表4
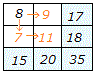
|
(さらに掘り下げて考えてみると)
本来,表と裏は等しい確率で出るはずであるが,試しに10回の試行を行ったとき,右のような結果になった場合,このコインを公平な材料として使えるかどうか判断したい.
(2) ところが,そもそも整数値の度数分布表から計算した「カイ2乗」の値を,数学で連続関数として定義されている「カイ2乗分布」に当てはめることができるのは,表の中に5よりも小さな値が登場しない場合で,5未満の数値が登場したら,「カイ2乗分布」曲線で近似することはできないと言われている.(イエーツの補正も賛否両論あり,使わない人もいるらしい) この表のように2×2の表では,カテゴリーの併合もできない(比較する対象がなくなってしまう). 結局,この表ではカイ2乗検定は適用できないので,確率を直接計算するしかない. その確率計算を実演してみる中で,このページで述べてきた「カイ2乗検定」について,補足説明を行ってみる. (3) 1回の試行で表が出る確率が となるが,「この確率」で判断するのではないことに注意. 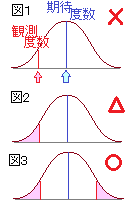 (4) 右図1のように,連続分布となっている確率分布関数において,ある特定の値をとる確率というものは考えない(線の面積は0).
(4) 右図1のように,連続分布となっている確率分布関数において,ある特定の値をとる確率というものは考えない(線の面積は0).したがって,期待度数と比較して観測度数がズレているときに,「そんなにズレることは,偶然的に起こり得るのか」という疑問に答えるときに,右図1のようにちょうどその値になる確率を求めているのではなく,図2のように「その値以上ズレることが,偶然的に起こり得るのか」どうかを計算することになる. |
||||||||||||||||||
|
10回の試行中,「表が2回以下」となる確率は
表が0回:
これらを加えて,図2で示した「表が2回以下」となる確率は,0.0547>.05となって,5%の有意差は認められない.表が1回: 表が2回: もっと,慎重に考えると,そもそも「表が2回以下」となる場合だけが公平でない訳でなく「表が8回以上=裏が2回以下」の場合も同様に公平でないと考えるのが普通で,図3で示した桃色部分を求める方がよい.(=両側検定にする) 表が8回,9回,10回となる確率も求めると,上記と同じ値になって,両側で合計は2倍になり,0.1094>.05だから,5%の有意差は認められない. 確率0.5であっても,このくらいの凹凸は珍しくないということになります. (5) それでは,度数分布表で最も小さい値が5以上あって,カイ2乗検定が適用できる場合に,上のように正確な確率で計算した場合と,カイ2乗検定の結果が同じになるかどうか実演してみる.(あまり大きな値を使うと,手書きの計算ができないだけでなく,Excelでも無理になることがあるので,控えめに!) ある都市の1月の初め25日間の冬日(最低気温が0°未満の日)について,平年の回数を期待度数とし,今年の回数を観測度数として表にすると,次のようなったとする. この表で,今年の冬日の回数が平年並みかどうかをカイ2乗検定で調べたい.
ii) 正確に確率計算で行うには,二項定理を用いて 1回につき確率 10/25=0.4で起こるはずのことが 25回中r回起こり,1回につき確率 15/25=0.6で起こるはずのことが25回中 (25−r)回起こる の和をExcelなどで計算すると(筆算では無理),0.15となるから,両側確率として0.30と考えれば,5%の有意差は認められない. ※カイ2乗で求めた確率は近似値ではあるが,この問題のように1桁程度の度数が含まれている場合には,あまりよい近似にならないようです. |
|
|
|
■[個別の頁からの質問に対する回答][カイ2乗分布について/17.2.8]
いま有斐閣の「統計学」2008年版を独習して、どうにもわからなくなって本サイトにお助けいただいているところです。大学生用の教科書だとはいえ、どうしてこれほどわかりにくいのかと困っていたところ助かりました。やはり、手で計算すると分かりやすくなると実感しています。EXCEL2013では少し関数が違うので、フォローしていただけるとなおうれしいです。
■[個別の頁からの質問に対する回答][カイ2乗分布(χ2分布)について/16.10.13]
=>[作者]:連絡ありがとう.関数が違うということはないと思いますが,画面上端のメニュー構成は変わっています. 最近のPCはあまり壊れないので,筆者はExcel2007までしか持っていません. とてもわかりやすいですが、
途中式をいれていただけるとありがたいです。
=>[作者]:連絡ありがとう.後半の「途中式」については,書けるものは書いているつもりですが,Excelがどんな処理をしているのかというようなことは全く書きえないことです・・・どの式とどの式の間という具合にもっと具体的に質問してください. |