【問題3.1】
次の表は,ある店で果物が売れた時間帯(0~23)を記録したものだとします.(架空データ)
-表3.2-
| みかん | りんご | かき |
| 7 | 18 | 15 |
| 11 | 20 | 3 |
| 5 | 21 | 5 |
| 19 | 7 |
| 10 | |
この表から,果物の種類と売れた時間帯の相関比を,上記のまとめ(1)~(4)の方法で求めてください.
特に,(4)の方法では,P-値を用いて,有意な群間変動があるといえるかどうかも判断してください.
(1) 次のように表を左から右へ,上から下へ書き込んで行き,最後に相関比を求める.(なお,Excel上は小数桁数が多いが,この画面上は小数第1位まで表示した)
| 時間帯 | 群内偏差 | 同2乗 | 全体偏差 | 同2乗 |
| みかん | 7 | −4 | 16 | −5.6 | 31.2 |
| みかん | 11 | 0 | 0 | −1.6 | 2.5 |
| みかん | 15 | 4 | 16 | 2.4 | 5.8 |
| りんご | 18 | 0.4 | 0.2 | 5.4 | 29.3 |
| りんご | 20 | 2.4 | 5.8 | 7.4 | 55.0 |
| りんご | 21 | 3.4 | 11.6 | 8.4 | 70.8 |
| りんご | 19 | 1.4 | 2.0 | 6.4 | 41.2 |
| りんご | 10 | −7.6 | 57.8 | −2.6 | 6.7 |
| かき | 15 | 7.5 | 56.3 | 2.4 | 5.8 |
| かき | 3 | −4.5 | 20.3 | −9.6 | 91.8 |
| かき | 5 | −2.5 | 6.3 | −7.6 | 57.5 |
| かき | 7 | −0.5 | 0.3 | −5.6 | 31.2 |
| みかん平均 | 11 | 和 | 192.2 | 和 | 428.9 |
| りんご平均 | 17.6 | | | 相関比 | 0.55 |
| かき平均 | 7.5 | | | | |
| 全体平均 | 12.6 | | | | |
(2)
みかん平均=11, りんご平均=17.6, かき平均=7.5, 全体平均=12.6だから
(群間変動)=(11−12.6)×3+(17.6−12.6)×5+(7.5−12.6)×4=236.7
(全変動)=428.9
(相関比)=236.7/428.9=0.55
(3)
みかんの分散=10.7→3倍→みかんの群内変動=32.0
りんごの分散=15.4→5倍→リンゴの群内変動=77.2
かきの分散=20.8→4倍→かきの群内変動=83.0
全体の分散=35.7→12倍→全変動=428.9
(相関比)=1−(32.0+77.2+83.0)/428.9=0.55
(4)
-表3.2-の形から,(Excelで)データ→データ分析→分散分析:一元配置に進む
列見出し(みかん~かき)も含めて,みかん,かきの空欄も含めて入力範囲を指定する.
| 概要 | |
| グループ | 標本数 | 合計 | 平均 | 分散 |
| みかん | 3 | 33 | 11 | 16 |
| りんご | 5 | 88 | 17.6 | 19.3 |
| かき | 4 | 30 | 7.5 | 27.7 |
| 分散分析表 |
| 変動要因 | 変動 | 自由度 | 分散 | 観測された
分散比 | P-値 | F 境界値 |
| グループ間 | 236.7 | 2 | 118.36 | 5.54 | 0.03 | 4.26 |
| グループ内 | 192.2 | 9 | 21.36 | | | |
| | | | | | |
| 合計 | 428.9 | 11 | | | | |
表により,(相関比)=236.7/428.9=0.55
P-値が0.03<0.05だから有意水準5%で群間変動が見られる
→閉じる←
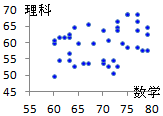
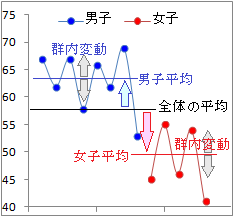
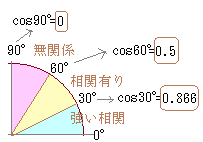 を「強い相関がある」に含めるのはおかしいとも言えます.
を「強い相関がある」に含めるのはおかしいとも言えます.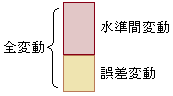 無相関検定は,(水準間変動)÷(誤差変動)を計算するF値もしくは,そのルートのt値を用いて行う.
無相関検定は,(水準間変動)÷(誤差変動)を計算するF値もしくは,そのルートのt値を用いて行う.